📌 文献信息 (Citation Info)
- 论文题目:A Survey of Deep Learning for Industrial Visual Anomaly Detection
- 发表期刊:Artificial Intelligence Review, 2025, 58:279,
- DOI: 10.1007/s10462-025-11287-7
- 官方资源库:GitHub - IHPCRits/IAD-Survey
- 延伸阅读(SOTA实现):GitHub - Dinomaly (CVPR 2025)
工业视觉异常检测 (Industrial Visual Anomaly Detection)
00. 综述核心贡献 (Scope & Contribution)
 覆盖范围:系统回顾 196 篇研究,梳理 5 种学习策略,并详细介绍 12 类方法。
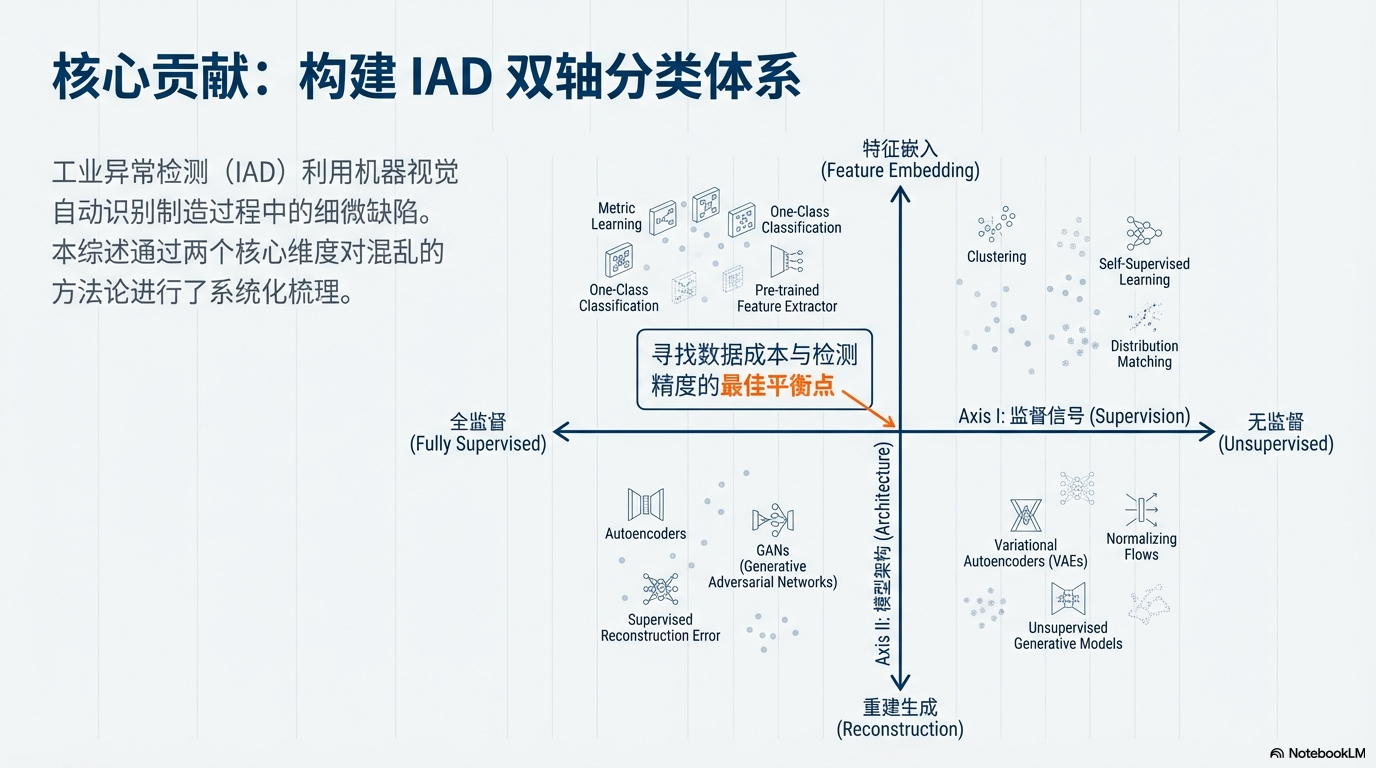
本文对深度学习在工业异常检测(IAD)领域的应用进行了系统化梳理,核心贡献在于构建了双轴分类体系:
覆盖范围:系统回顾 196 篇研究,梳理 5 种学习策略,并详细介绍 12 类方法。
本文对深度学习在工业异常检测(IAD)领域的应用进行了系统化梳理,核心贡献在于构建了双轴分类体系:
- 基于监督信号(Supervision):将方法划分为从全监督到无监督的 5 大范式。
- 基于模型架构(Architecture):提炼出 特征嵌入 (Embedding) 与 重建生成(Reconstruction) 两大技术主线。
- 落地导向:不仅覆盖了 2D/3D 数据集,还深入探讨了“阈值敏感度”、“逻辑异常”及“边缘部署”等工业痛点。
01. 背景:工业检测的“六大挑战”
定义:利用机器视觉自动识别制造过程中的缺陷。与通用异常检测(AD)相比,工业场景具有**“细微、特定、高代价”**的特征。
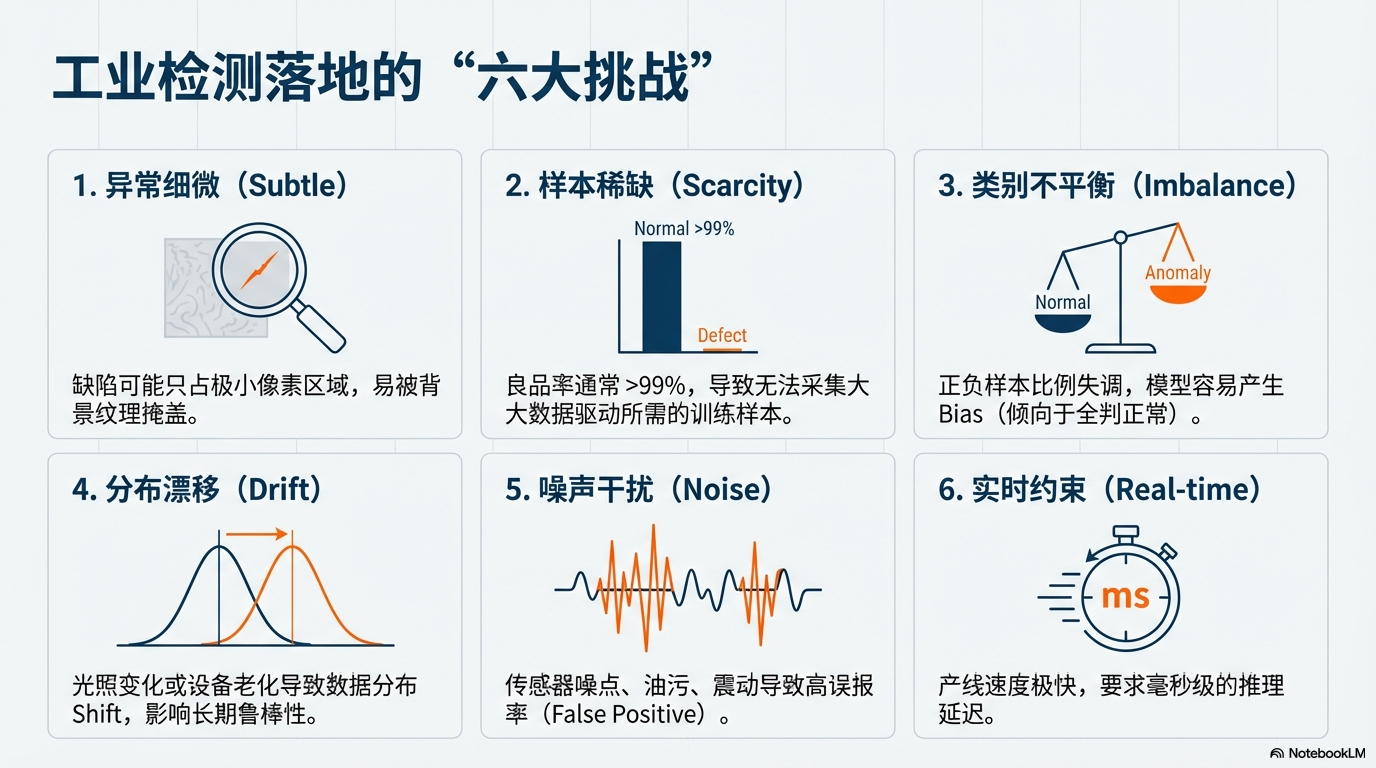
为什么工业检测难落地?
对照上图六大挑战,核心痛点在于:
-
特征隐蔽:缺陷极微小且纹理复杂 ➡️传统 CNN 易漏检,需高分辨率感知。**
-
数据极偏:良品率 >99% 且长尾分布 ➡️无法依赖大数据训练,模型易判“全员正常”。**
-
环境恶劣:光照漂移与传感器噪声 ➡️模型必须具备极强的抗干扰鲁棒性 (Robustness)。**
-
速度铁律:产线毫秒级节拍 ➡️高精度模型难以在边缘端实时部署。**
02. 方法论 I:五大学习范式 (Taxonomy by Supervision)
按标注成本从高到低排序。请根据实际数据条件进行选型:
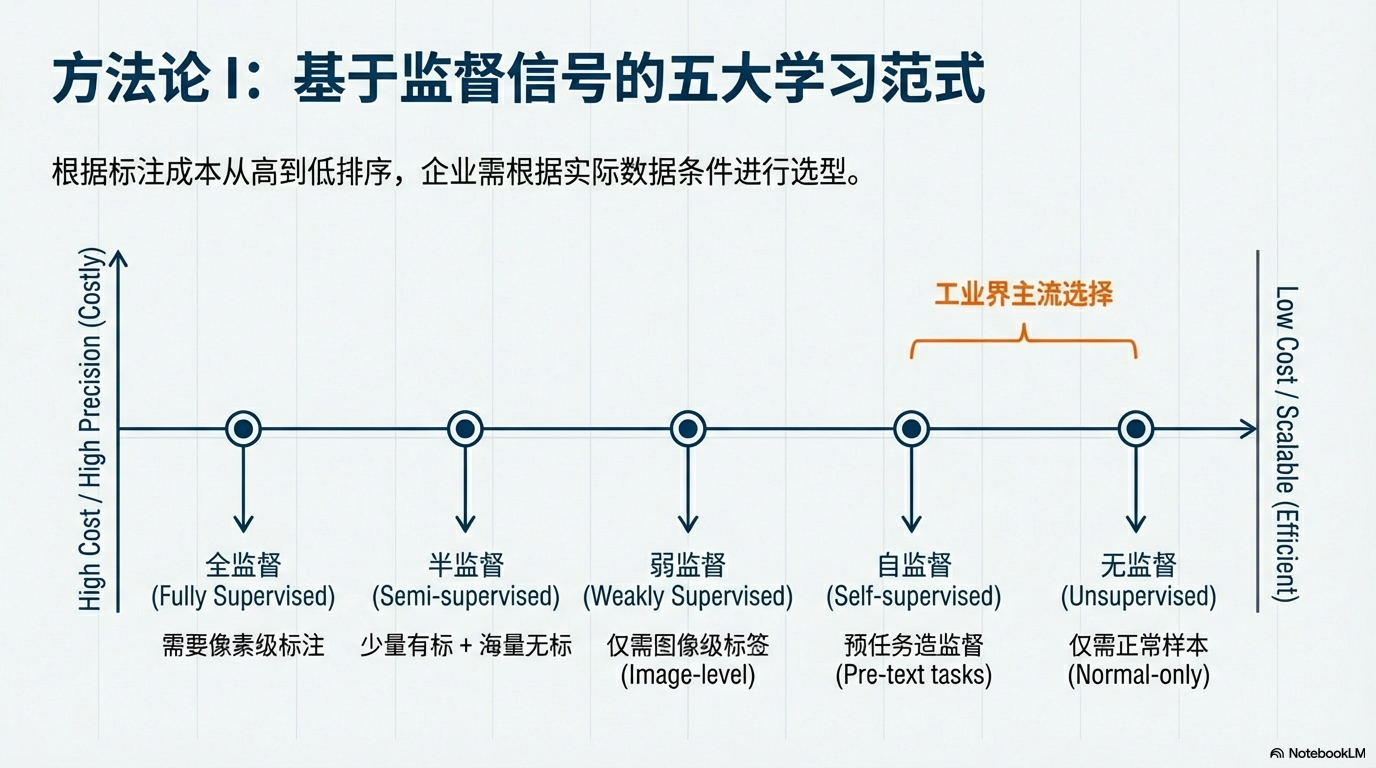
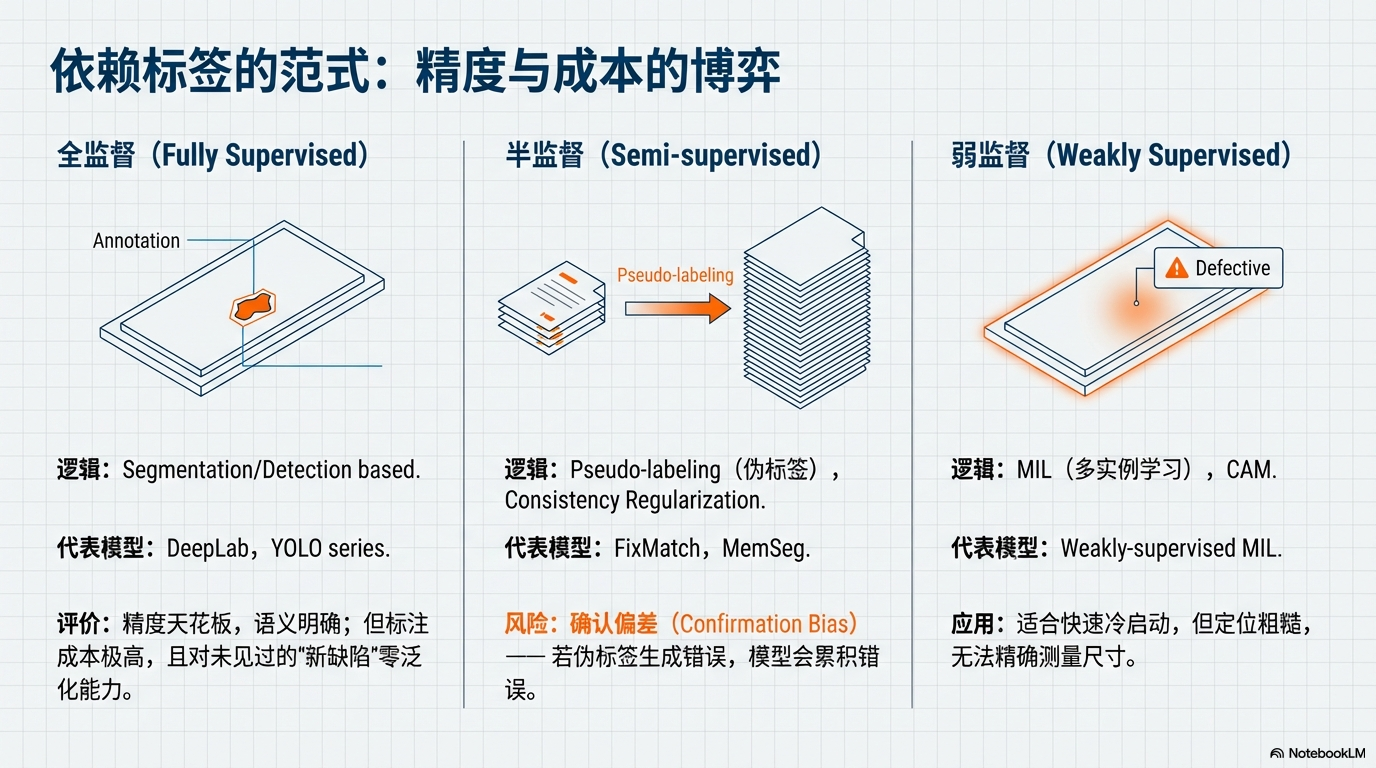
1️⃣ 全监督 (Fully Supervised)
- 数据条件:正常样本 + 所有类别异常样本 + 像素级标注。
- 方法族:Segmentation (分割), Detection (检测)。
- 代表模型:DeepLab, Mask R-CNN, YOLO series。
- 优势:语义明确,精度天花板,能区分具体缺陷种类。
- 痛点:标注成本极高;零泛化能力(对训练集中未出现的“新缺陷”无法识别)。
2️⃣ 半监督 (Semi-supervised)
- 数据条件:少量有标数据 + 海量无标数据。
- 方法族:Pseudo-labeling (伪标签), Consistency Regularization (一致性正则)。
- 代表模型:GANomaly / DifferNet, MemSeg。
- 优势:利用廉价的无标数据提升模型对边缘 Case 的鲁棒性。
- 痛点:标注成本极高;对训练集中未出现的新缺陷泛化显著受限(需增广/合成异常/开放集策略辅助)。
3️⃣ 弱监督 (Weakly Supervised)
- 数据条件:仅需图像级标签(Image-level: 良/不良),无需像素级标注。
- 方法族:MIL (多实例学习), CAM (类激活映射)。
- 代表模型:Weakly-supervised MIL approaches。
- 优势:标注效率高,适合快速冷启动。
- 痛点:定位粗糙,难以精确测量缺陷尺寸;抗背景噪声能力弱。
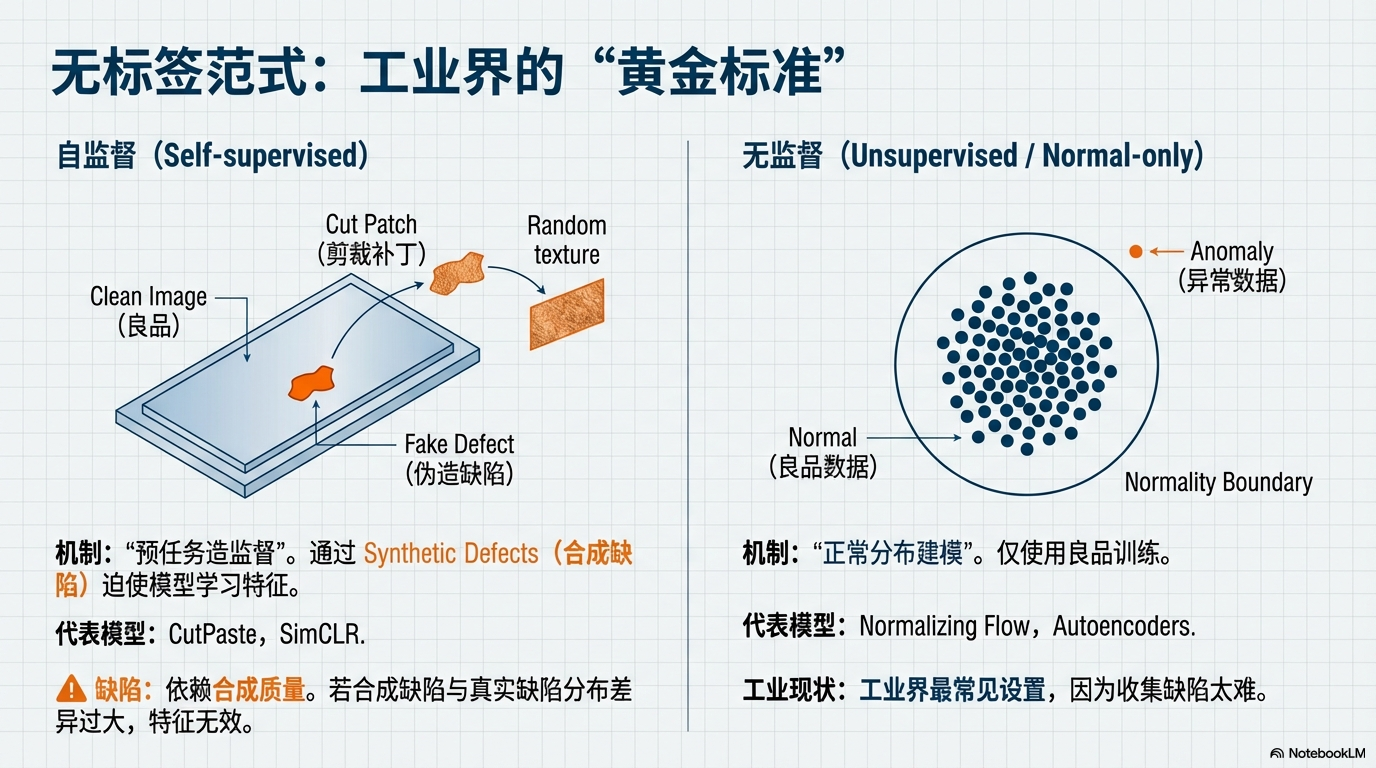
4️⃣ 自监督 (Self-supervised) —— “预任务造监督”
- 数据条件:无标签(通过构造辅助任务学习特征)。
- 方法族:Synthetic Defects (合成缺陷), Contrastive Learning (对比学习)。
- 代表模型:CutPaste, SimCLR, NSA。
- 优势:迫使模型学习数据的内在结构,无需人工标注。
- 痛点:依赖预任务设计——若合成的缺陷(如随机剪贴)与真实缺陷分布差异过大,特征无效。
5️⃣ 无监督 (Unsupervised) —— “正常分布建模”
- 数据条件:仅需正常样本 (Normal-only) 训练。
- 方法族:Reconstruction (重建), Embedding (特征记忆), Flow (流模型)。
- 代表模型:Autoencoder (AE), PatchCore, FastFlow, GAN。
- 优势:零缺陷启动,理论上能发现任何偏离正常的“未知异常”。
- 痛点:阈值敏感;易产生高误报(将正常品的轻微波动误判为异常)。
03. 方法论 II:核心机制与架构 (Mechanism & Architecture)
深度学习方法在机制上主要分为两大流派:基于特征嵌入 与 基于重建生成。
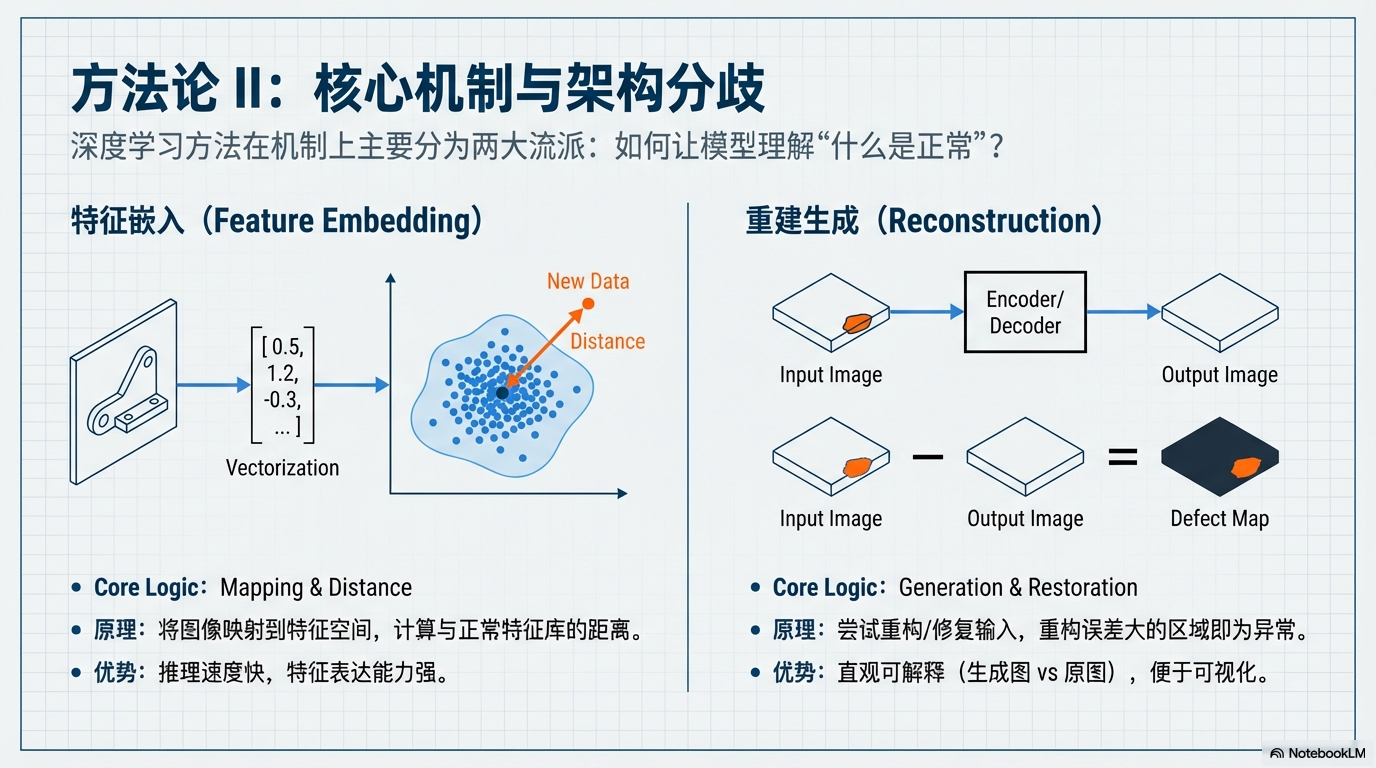
⚔️ 两大技术主线对比
| 维度 | 特征嵌入 (Feature Embedding) | 重建生成 (Reconstruction) |
|---|---|---|
| 核心逻辑 | Mapping & Distance 将图像映射到特征空间,计算与正常特征库的距离。 | Generation & Restoration 尝试重构/修复输入,重构误差大的区域即为异常。 |
| 主流方法族 | 1. Teacher-Student (蒸馏差异) 2. Memory Bank (特征库匹配) 3. Normalizing Flow (概率密度估计) | 1. Autoencoder (压缩-解码) 2. GAN (生成-判别) 3. Diffusion (去噪-修复) |
| 代表模型 | SPADE, PatchCore, FastFlow | AE, DRAEM, AnoGAN, DDPM-based |
| 核心优势 | 推理速度快,特征表达能力强(尤其利用预训练模型)。 | 直观可解释(生成图 vs 原图),便于可视化。 |
| ⚠️ 典型失效模式 | Domain Shift (域漂移) 如果预训练特征提取器不适应当前工业纹理,距离度量会失效。 | Identity Mapping (恒等映射) 模型过于强大,把异常也完美重构了,导致漏检。 |
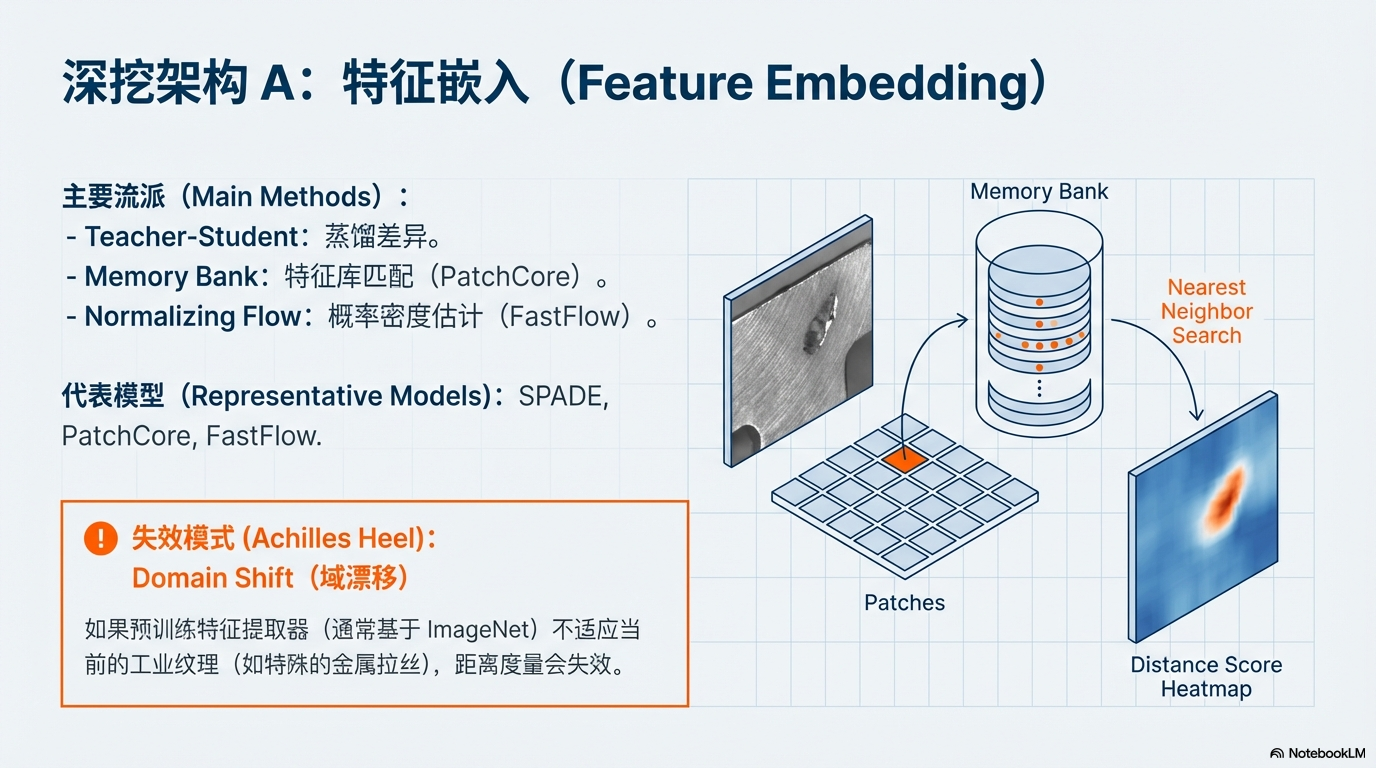 | ||
| 特征嵌入 (Feature Embedding) |
-
原理:Mapping & Distance。将图像映射到特征空间,比对与正常库的距离。
-
代表:PatchCore, Teacher-Student。
-
⚠️ 失效模式:Domain Shift (域漂移)。若预训练特征提取器不适应工业特定纹理(如特殊金属拉丝),距离度量将失效。
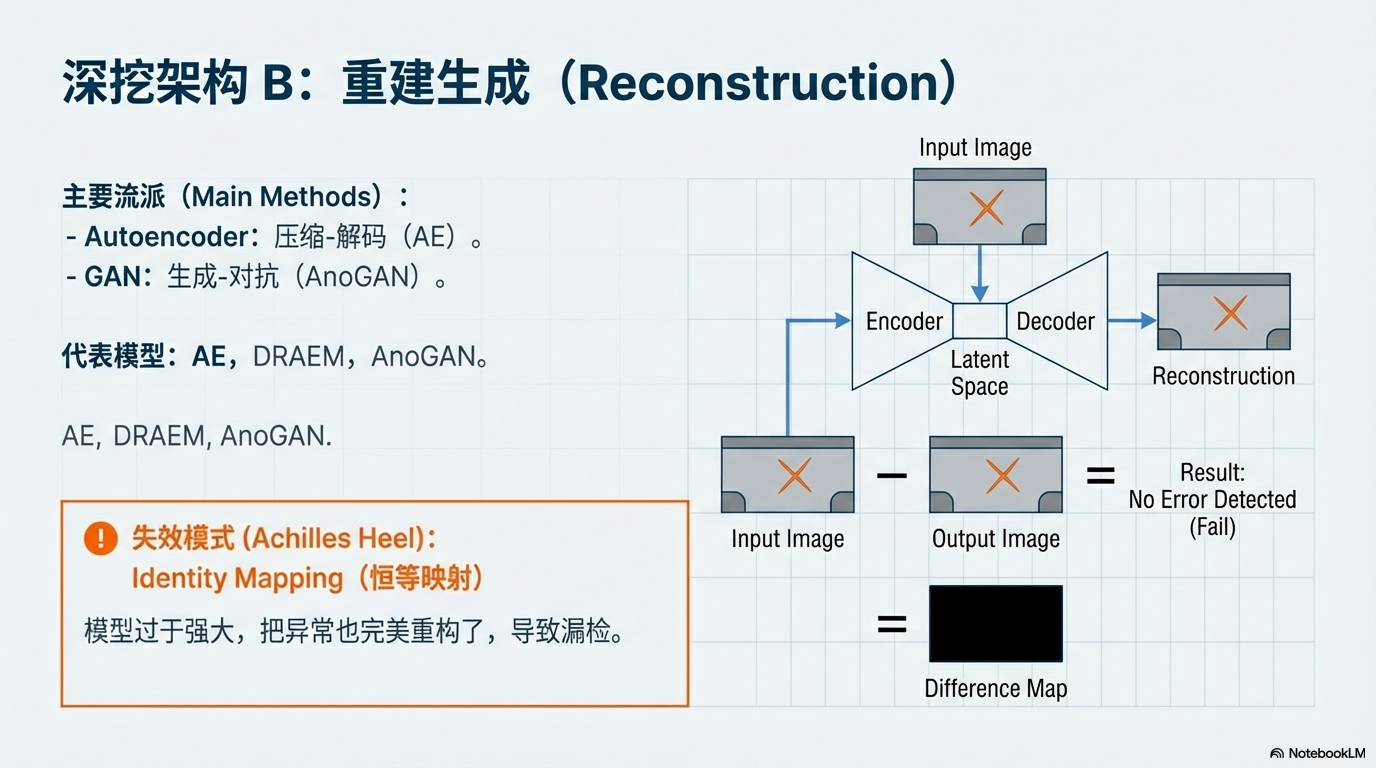 重建生成 (Reconstruction)
重建生成 (Reconstruction) -
原理:Generation & Restoration。尝试修复输入,重构误差 (Difference Map) 即为缺陷。
-
代表:Autoencoder, GAN, Diffusion。
-
⚠️ 失效模式:Identity Mapping (恒等映射)。模型若过于强大(过拟合),会把异常也完美还原,导致漏检。
🚀 前沿架构演进
- Transformer:解决 CNN 感受野受限问题,利用 Global Attention 捕捉长距离依赖(如大面积色差、纹理渐变)。
- Diffusion Models:从“生成”转向“修复”。将缺陷视为噪声,通过迭代去噪实现像素级精细定位,但推理速度是瓶颈。
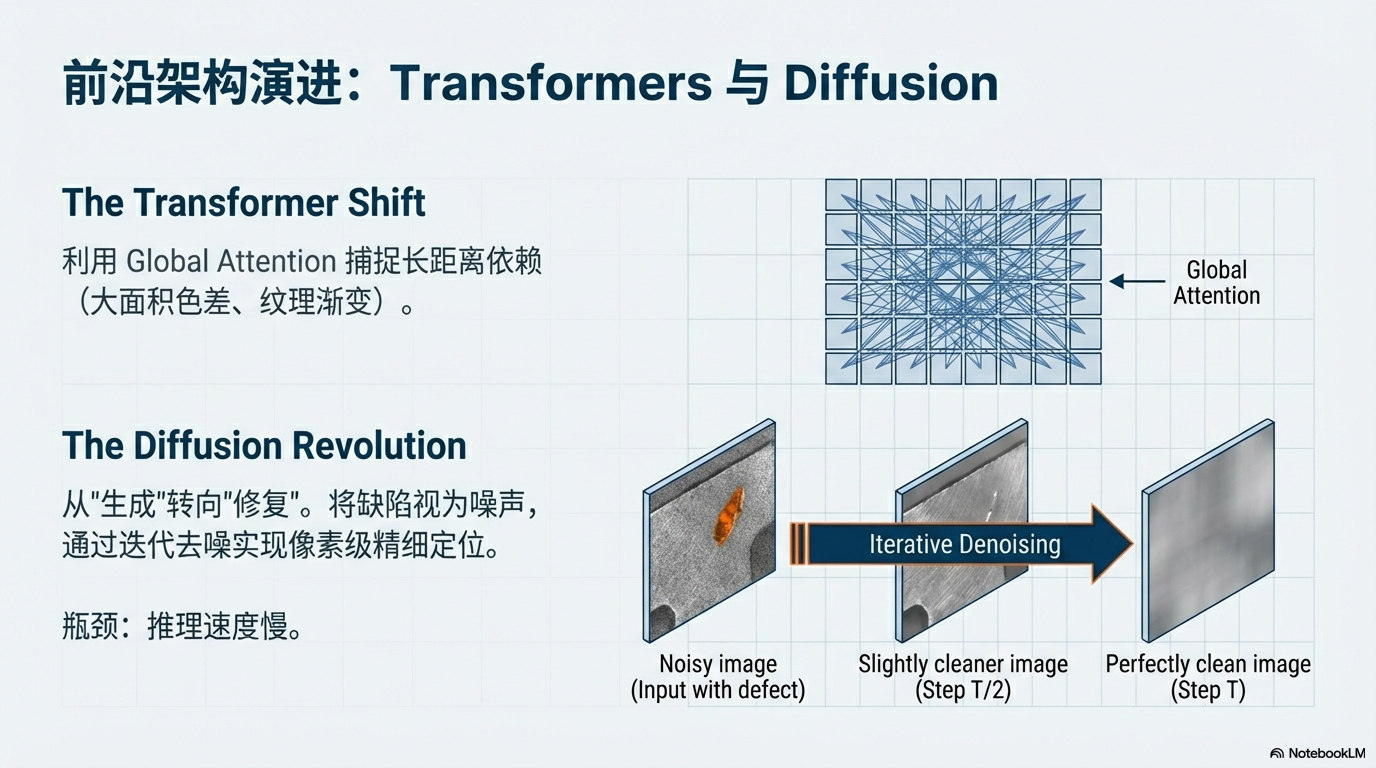
💡 Takeaway: 当前Embedding/Flow 系在多基准上长期强势;Diffusion 正在快速进入高精度定位路线,但推理效率仍是核心瓶颈。
04. 数据集与评估:工业落地视角
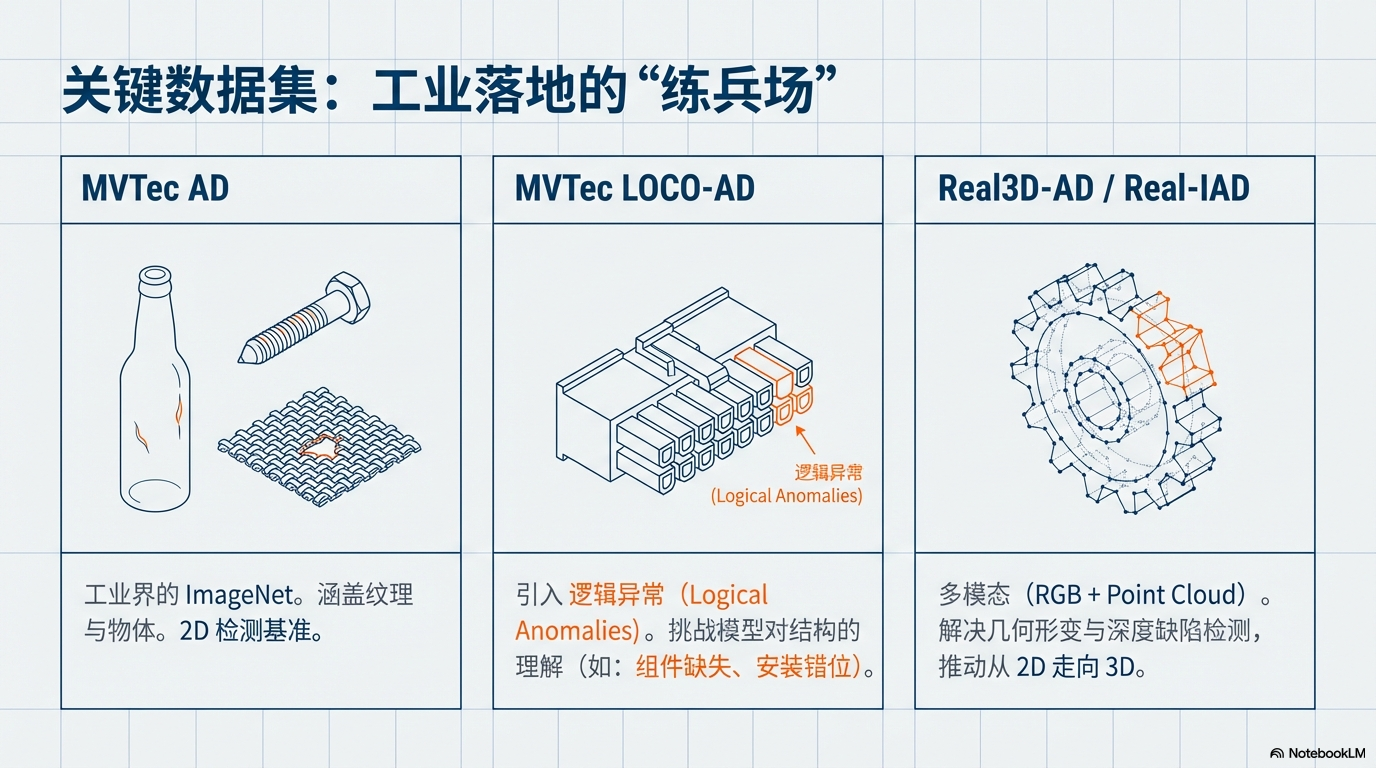
📚 关键数据集 (Datasets)
- MVTec AD (图左):工业界的 ImageNet。考察对纹理与物体的基础检测能力。
- MVTec LOCO-AD (图中):逻辑异常试金石。考察模型能否理解“螺丝少装、线缆插错”等结构性问题。
- Real3D-AD (图右):多模态挑战。引入点云与多视角,解决几何形变与深度缺陷。
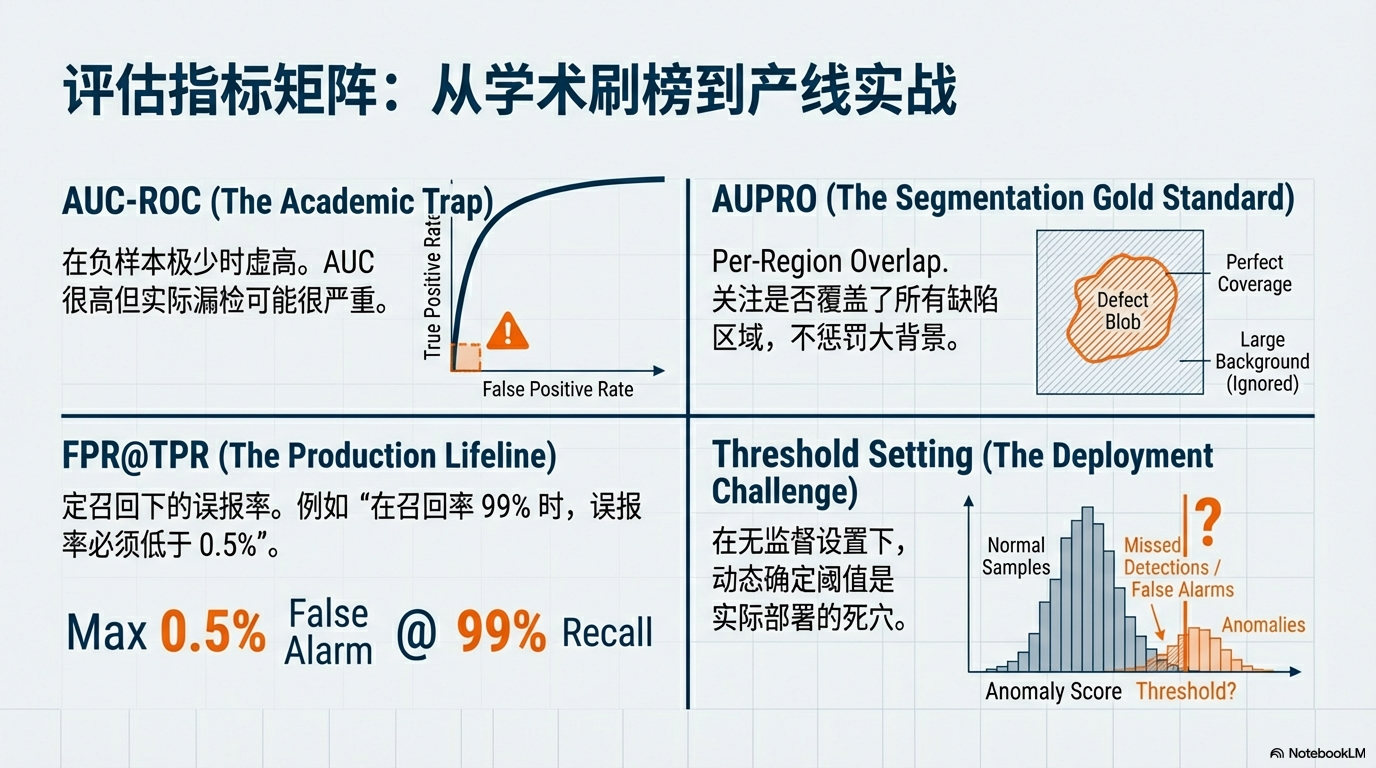
📏 关键指标 (Metrics Matrix)
| 指标类型 | 推荐指标 | 工业含义 | 落地避坑指南 |
|---|---|---|---|
| 分类性能 (Image-level) | AUC-ROC | 区分良/不良品的能力 | ⚠️ 虚高陷阱:在负样本极少时,AUC 很高但实际漏检可能很严重。 |
| 定位性能 (Pixel-level) | AUPRO | 区域重叠率 (Per-Region Overlap) | ✅ 黄金标准:比 IoU 更科学,它关注是否覆盖了所有缺陷区域(无论大小),不惩罚大背景。 |
| 运维性能 (Production) | FPR@TPR | 定召回下的误报率 | ✅ 产线生命线:例如“在召回率 99% 时,误报率必须低于 0.5%”,否则会显著增加人工复检成本。 |
| 阈值策略 | F1-max | 最佳阈值下的 F1 | ⚠️ 落地难点:学术界常用 F1-max,但在实际部署中,如何动态确定这个阈值是无监督方法的关键难点/主要瓶颈。 |
 |
05. 趋势与展望 (Future Directions)
-
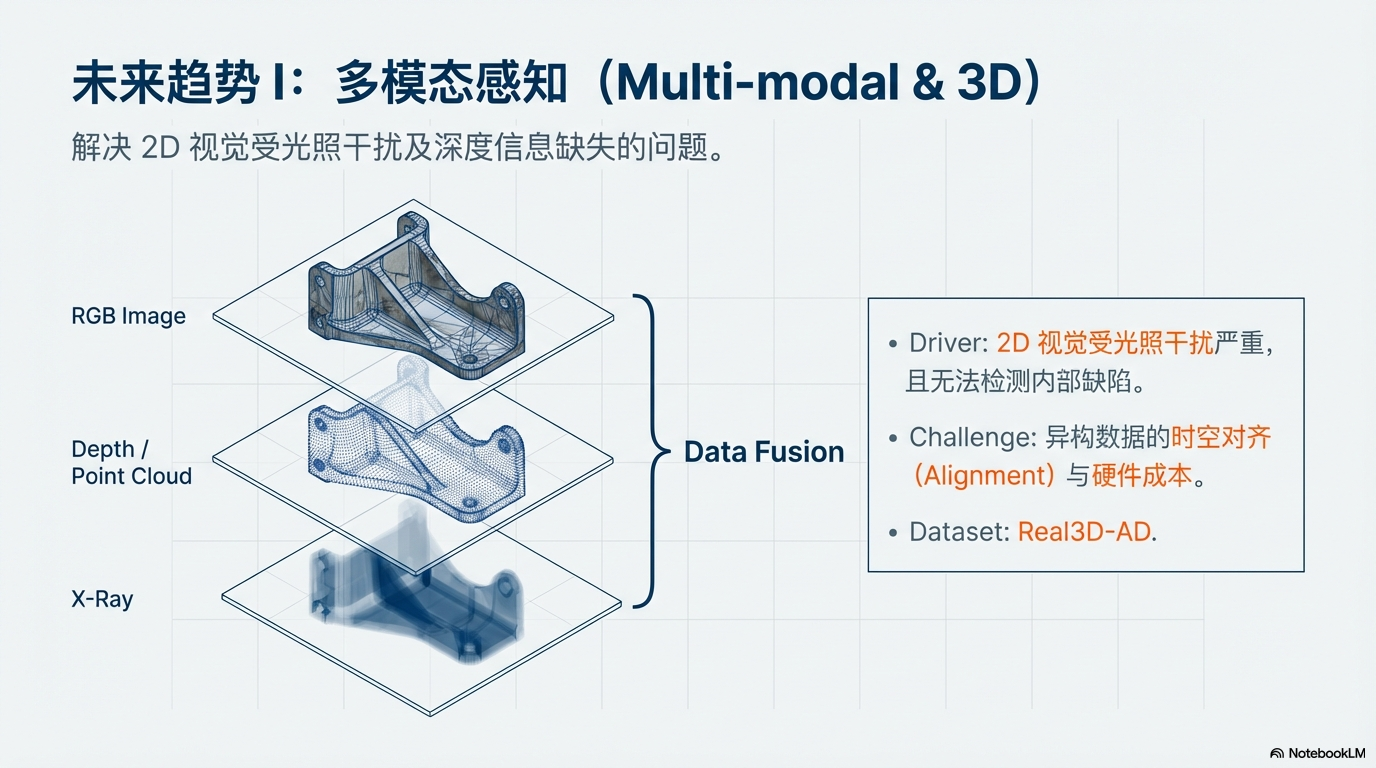
从 2D 走向 3D 多模态
- 动因:光照干扰严重,或缺陷位于内部/深度方向。
- 方向:融合 RGB、深度图 (Depth)、点云甚至 X-Ray。
- 难点:异构数据的时空对齐 (Alignment) 与高昂的硬件/算力成本。
-
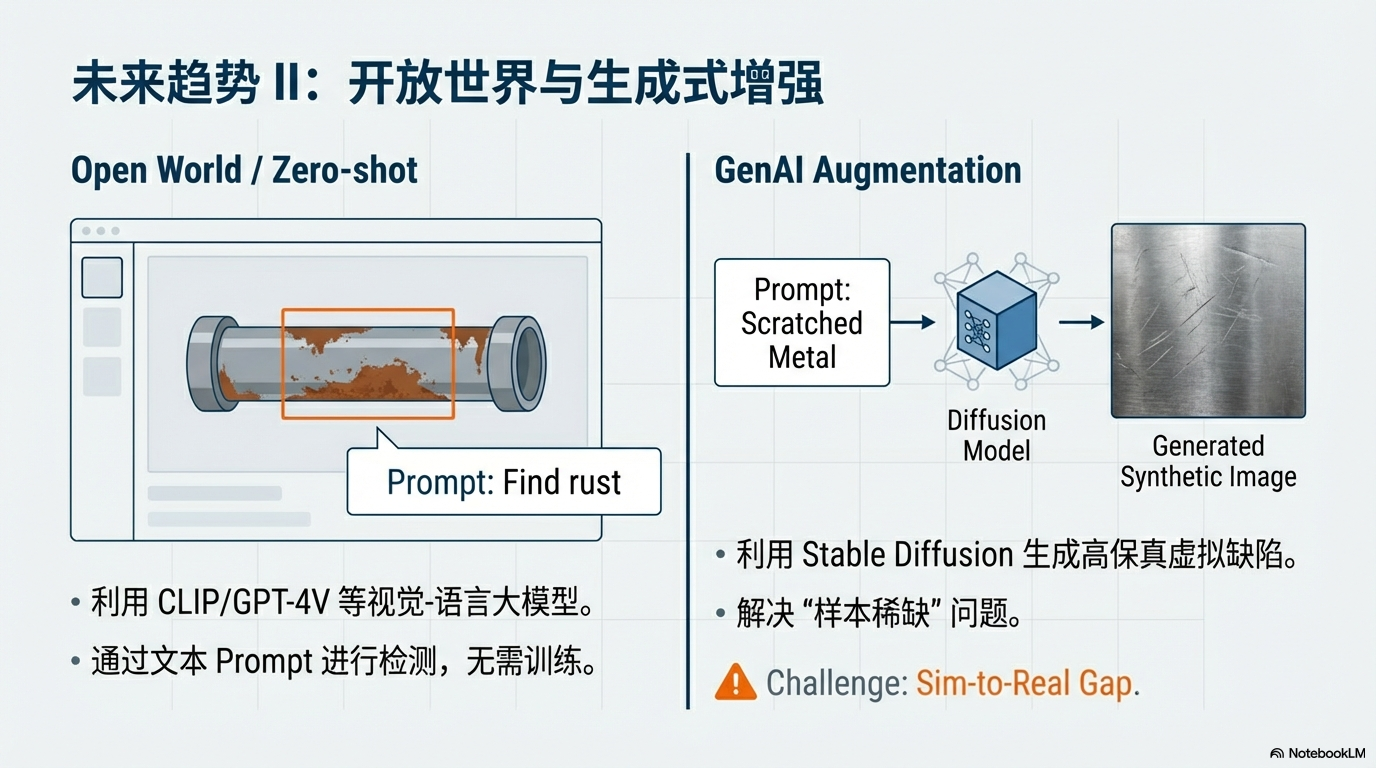
开放世界检测 (Open World / Zero-shot)
- 动因:新产品上线快,无训练数据;需检测未定义的“异常”。
- 方向:利用 CLIP/GPT-4V 等视觉-语言大模型,通过文本 Prompt(如“生锈”)进行检测。
- 难点:通用大模型对工业微小瑕疵 (Tiny Defects) 的理解精度远不如专用小模型。
-
生成式数据增强 (GenAI Augmentation)
- 动因:真实缺陷数据极度匮乏。
- 方向:利用 Stable Diffusion 或 GAN 生成高保真的虚拟缺陷样本用于训练。
- 难点:Sim-to-Real Gap——生成的缺陷若不够真实,反而会作为噪声干扰模型训练。
-
端侧部署与隐私 (Edge & Privacy)
- 动因:数据不出厂(安全),毫秒级响应(实时)。
- 方向:模型量化 (Int8)、知识蒸馏、联邦学习 (Federated Learning)。
- 难点:在将模型压缩 10 倍的同时,如何保持 AUPRO 指标不下降。
💡 Takeaway: 未来的工业检测系统将是 “多模态感知” (眼睛) + “大模型泛化” (大脑) + “边缘高效计算” (手脚) 的有机结合。
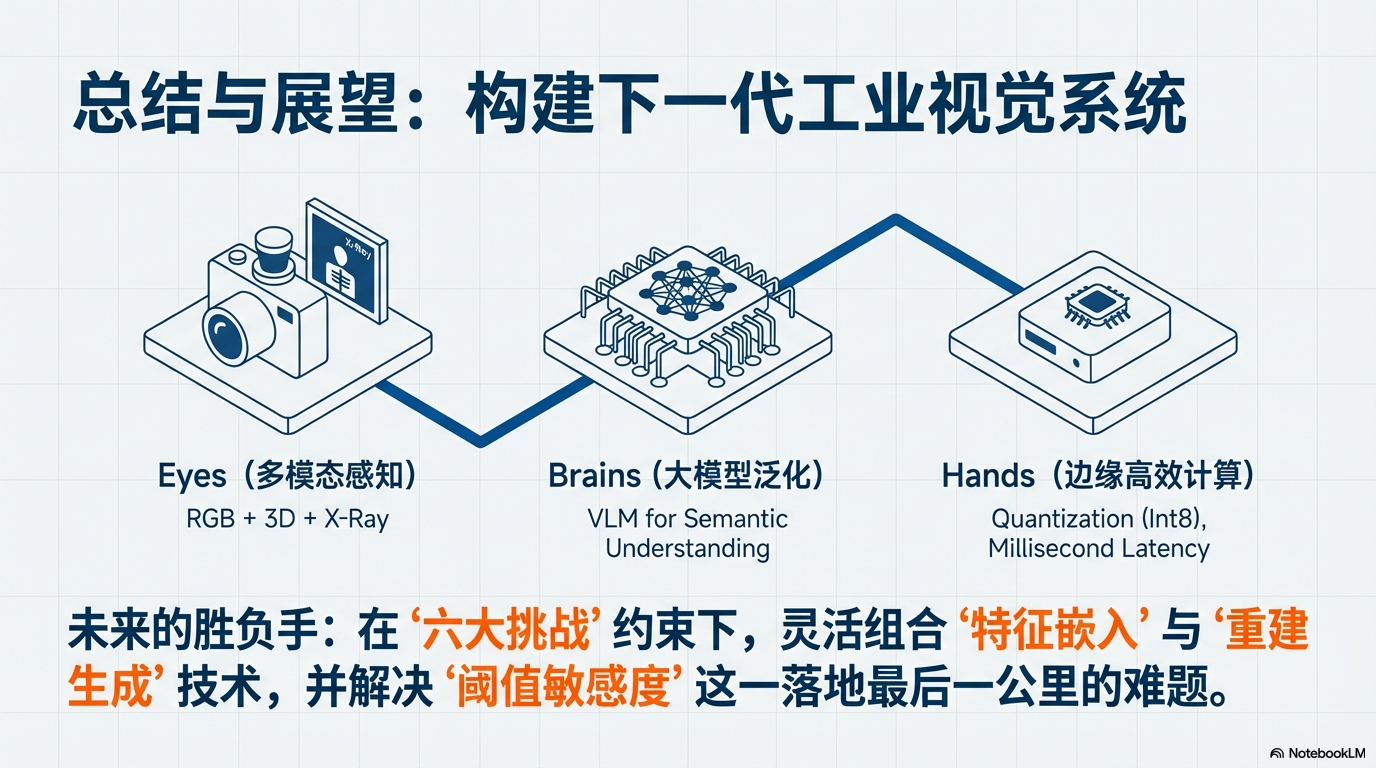 🚀 下一代工业视觉系统:Eyes, Brains & Hands
🚀 下一代工业视觉系统:Eyes, Brains & Hands
-
👀 Eyes:多模态感知 (Multi-modal & 3D)
-
痛点:2D 图像无法检测内部气泡或深度划痕。
-
趋势:RGB + Depth + Point Cloud 融合,实现全方位几何感知。
-
-
🧠 Brains:大模型泛化 (Open World / VLM)
-
痛点:新产品上线无训练数据。
-
趋势:利用 CLIP/GPT-4V 理解文本指令(如“找出生锈”),实现零样本 (Zero-shot) 检测。
-
-
🛠️ Hands:边缘高效计算 (Edge Computing)
-
痛点:云端推理延迟高,数据隐私敏感。
-
趋势:模型量化 (Int8) + 联邦学习。在边缘端毫秒级响应,同时保护工厂数据隐私。
-
06. 总结与行动建议 (Summary & Practical Takeaways)
6.1 三句话总结(What did we learn)
-
问题本质:工业视觉异常检测(IAD)不是普通分类任务,而是在极度不平衡数据下,对细微缺陷进行高精度识别与定位,并长期应对分布漂移、噪声干扰与实时延迟等工业约束。
-
方法全景:现有方法可用双轴框架统一理解——监督信号(5类学习范式)× 检测机制(Embedding vs Reconstruction):前者决定“你能用什么数据训练”,后者决定“模型凭什么看出异常”。
-
落地关键:工业部署成败往往不只取决于模型本身,而取决于阈值与误报控制、域漂移鲁棒性、算力/延迟预算三者的系统性权衡。
6.2 五条“带走就能用”的结论(So what)
-
选范式先看数据条件:
-
有像素级标注 → 全监督(精度上限高,适合已知缺陷与精确分类/分割);
-
只有少量缺陷标注 + 大量无标 → 半监督(用伪标签/一致性提升性价比);
-
只有良/不良(OK/NG) → 弱监督(MIL/CAM做粗定位,适合快速冷启动);
-
Normal-only(只收集到正常样本) → 无监督/单类学习(工业中最常见的起步设置之一)。
-
-
Embedding 路线更偏“效率与稳定基线”:
特征库/蒸馏/Flow 等方法通常推理速度快、工程实现成熟,适合纹理一致、缺陷细微、需要高吞吐的产线场景(但要重点防“域漂移导致距离失真”)。 -
Reconstruction 路线更偏“可解释与精定位”:
AE/GAN/Diffusion 等方法通过“重建/修复”给出直观的异常残差图,适合结构复杂、需要可解释可视化定位的场景(但要防“恒等映射/过强重建把异常也重构掉”)。 -
评估不要只看 Image-AUC:
-
做分拣(Pass/Fail)看 Image-AUROC / F1;
-
做定位(找哪里坏)重点看 AUPRO(或PRO);
-
上产线一定要加 FPR@TPR(固定召回下的误报率),因为误报会直接带来人工复检成本。
注:FPR@TPR 属于部署 KPI/工程实践补充;学术评测常用 AUROC/PRO/AUPRO 等。
-
-
未来方向是“组合拳”,而非单点 SOTA:
IAD 正在走向 多模态感知(眼睛)+ 大模型泛化(大脑)+ 边缘高效计算(手脚) 的系统形态:多视角/3D/多模态提升覆盖范围,VLM/基础模型提升开放世界能力,蒸馏/量化/联邦学习保证可部署与隐私安全。
6.3 推荐的复现与实验路线(How to proceed)
目标:用最小成本建立“可比较、可落地”的实验闭环。
Step 1|基线建立(2D入门)
- 在 MVTec AD 上跑 1–2 个强基线(如 Embedding/Flow 路线),记录:
Image-AUROC + Pixel-AUROC + AUPRO,并保存典型可视化结果(Anomaly Map)。
Step 2|逻辑异常检验(从“纹理缺陷”走向“结构/语义异常”)
- 切换到 MVTec LOCO-AD,对比“结构异常 vs 逻辑异常”的失败案例:
明确模型到底是“不会看结构”还是“阈值/鲁棒性问题”。
Step 3|面向产线的阈值与误报控制(部署前必做)
-
设定目标召回(例如 TPR=99%),报告 FPR@TPR;
-
尝试阈值策略:固定阈值、按类别阈值、滑动窗口校准、漂移监控(Drift monitoring)。
Step 4|进阶方向(按资源选择其一)
-
若关注“更精细定位/可解释”:探索 Diffusion-based 修复/残差路线;
-
若关注“复杂几何缺陷”:引入 3D/多视角/多模态数据;
-
若关注“可部署”:做 蒸馏/量化(INT8)/边云协同,并评估延迟与吞吐。
工业异常检测的核心不是“刷一个指标”,而是在真实约束下把“效率 × 定位 × 误报控制”做成可长期稳定运行的系统。